[python] 데이터 전처리 - 피처 스케일링
<데이터 전처리 - 피처 스케일링>
데이터 전처리를 할 때, 서로 다른 변수의 값 범위를 일정한 수준으로 맞추는 작업을 해야할 경우가 있다. 이를 피처 스케일링이라 한다. 피처 스케일링 방법 중 StandardScaler와 MinMaxScaler를 이용하여 iris 데이터를 스케일링 해볼 것이다.
<StandardScaler>
StandardScaler는 데이터를 평균이 0, 분산이 1인 표준 정규분포를 따르도록 변환하는 표준화를 지원하는 클래스이다. ML 알고리즘에서 서포트 벡터 머신, 선형회귀, 로지스틱회귀 알고리즘은 데이터가 정규분포를 따른다고 가정하기 때문에 데이터를 표준화 시켜주면 예측 성능 향상에 큰 도움이 될 수 있다.
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
import pandas as pd
iris = load_iris()
iris_data = iris.data
iris_df = pd.DataFrame(iris_data, columns = iris.feature_names)
scaler = StandardScaler()
scaler.fit(iris_df)
iris_scaled = scaler.transform(iris_df)
iris_df_scaled = pd.DataFrame(iris_scaled, columns = iris.feature_names)
print('feature들의 평균값')
print(iris_df_scaled.mean())
print('\nfeature들의 분산값')
print(iris_df_scaled.var())
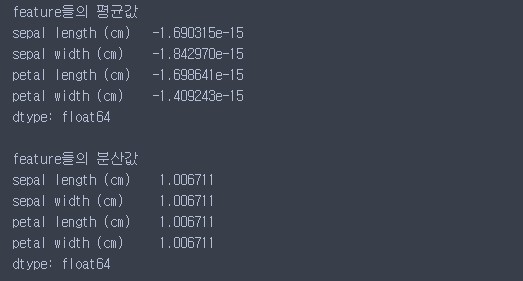
iris 데이터의 모든 칼럼 값의 평균이 0에 아주 가까운 값으로, 분산은 1에 가까운 값으로 변환된 것을 알 수 있다.
<MinMaxScaler>
MinMaxScaler는 데이터의 값을 0과 1사이의 범위 값으로 변환한다. 음수 값이 있으면 -1과 1사이의 값으로 변환한다. 변환 방식은 특정 데이터 값에서 최솟값을 뺀 값을 데이터의 최대값과 최솟값의 차로 나누어 계산한다.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(iris_df)
iris_scaled = scaler.transform(iris_df)
iris_df_scaled = pd.DataFrame(iris_scaled, columns = iris.feature_names)
print('feature들의 최솟값')
print(iris_df_scaled.min())
print('\nfeature들의 최댓값')
print(iris_df_scaled.max())
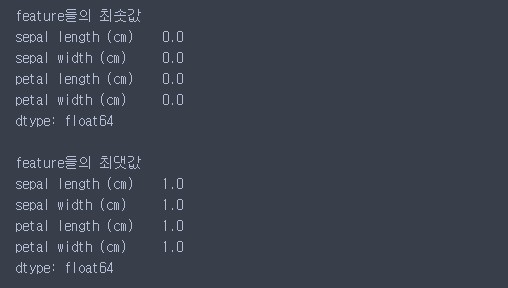
모든 피처의 최솟값이 0, 최댓값이 1로 변환된 것을 알 수 있다.
