[python] GridSearchCV 하이퍼파라미터 튜닝을 이용한 iris 데이터 분류
<GridSearchCV>
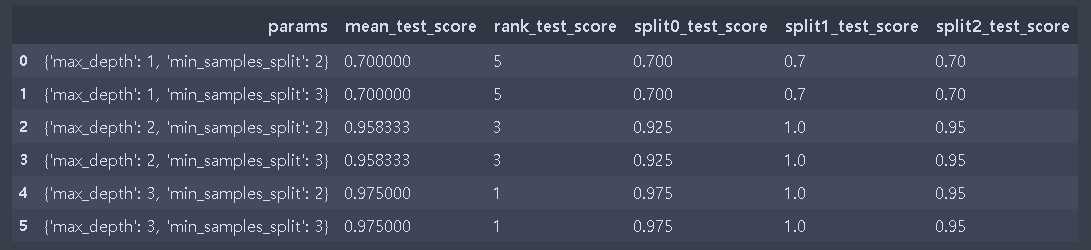
머신러닝을 수행할 때, 알고리즘을 구성하는 하이퍼 파라미터를 잘 설정하는 것도 하나의 중요한 이슈이다. sklearn에는 GridSearchCV API를 통해 하이퍼 파라미터를 순차적으로 입력하면서 편리하게 최적의 파라미터를 도출할 수 있다. 아래에서는 iris 데이터로 이 GridSearchCV를 이용하여 DecisionTree의 max_depth와 min_samples_split을 각각 (1, 2, 3), (2, 3)으로 적용하여 총 6가지 경우의 수에 대해 머신러닝 학습을 수행해 볼것이다.
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.metrics import accuracy_score
import pandas as pd
iris_data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size = 0.2, random_state=121)
dtree = DecisionTreeClassifier()
parameters = {'max_depth':[1, 2, 3], 'min_samples_split':[2, 3]}
grid_dtree = GridSearchCV(dtree, param_grid = parameters, cv=3, refit=True)
grid_dtree.fit(X_train, y_train)
scores_df = pd.DataFrame(grid_dtree.cv_results_)
print(scores_df[['params', 'mean_test_score', 'rank_test_score',
'split0_test_score', 'split1_test_score', 'split2_test_score']])
print('GridSearchCV 최적 파라미터:', grid_dtree.best_params_)
print('GridSearchCV 최고 정확도:{0:.4f}'.format(grid_dtree.best_score_))
estimator = grid_dtree.best_estimator_
pred = estimator.predict(X_test)
print('테스트 데이터 세트 정확도: {0:.4f}'.format(accuracy_score(y_test, pred)))