[python] 데이터 전처리 - 레이블 인코딩, 원핫 인코딩
<데이터 전처리 - 인코딩>
sklearn으로 머신러닝을 수행할 때, 문자열 값을 입력값으로 사용할 수 없기 때문에 문자열 값을 숫자 형으로 인코딩해야 한다.
인코딩 방법 중 대표적으로 레이블 인코딩과 원-핫 인코딩이 있는데 예시와 함께 사용법을 알아보겠다.
(원본 데이터) items = [‘TV’, ‘냉장고’, ‘전자레인지’, ‘컴퓨터’, ‘선풍기’, ‘선풍기’, ‘믹서’, ‘믹서’]
<레이블 인코딩>
레이블 인코딩은 카테고리 피처를 코드형 숫자 값으로 변환하는 것이다. sklearn.preprocessing 에서 LabelEncoder 클래스를 사용한다.
from sklearn.preprocessing import LabelEncoder
items = ['TV', '냉장고', '전자레인지', '컴퓨터', '선풍기', '선풍기', '믹서', '믹서']
encoder = LabelEncoder()
encoder.fit(items)
labels = encoder.transform(items)
print('인코딩 변환값:', labels)

<원-핫 인코딩 - OneHotEncoder>
레이블 인코딩으로 카테고리를 변환할 경우 결과 값이 1, 2와 같이 나타나게 되는데 특정 머신러닝 알고리즘에서 숫자가 크면 가중치가 부여될 수 있는 단점이 있다. 이러한 점을 해결하기 위해 2차원 배열로 특정 피처에 해당되는 칼럼에만 1을 표시하고 나머지는 0으로 나타내는 원-핫 인코딩을 사용한다.
다음은 sklearn.preprocessing에서 OneHotEncoder 클래스를 이용한 방법이다. 주의할 점이 있다면 OneHotEncoder의 입력 값은 숫자 형이어야 하고, 2차원 데이터가 필요하다는 것이다. 따라서 LabelEncoder로 먼저 문자열을 숫자 형으로 변환하고 numpy의 reshape을 이용하여 2차원 데이터로 변환할 것이다.
from sklearn.preprocessing import OneHotEncoder
import numpy as np
items = ['TV', '냉장고', '전자레인지', '컴퓨터', '선풍기', '선풍기', '믹서', '믹서']
#LabelEncoder로 2차원 데이터로 변환
encoder = LabelEncoder()
encoder.fit(items)
labels = encoder.transform(items)
labels = labels.reshape(-1, 1)
#원-핫 인코딩
oh_encoder = OneHotEncoder()
oh_encoder.fit(labels)
oh_labels = oh_encoder.transform(labels)
print('원-핫 인코딩 데이터')
print(oh_labels.toarray())
print('원-핫 인코딩 데이터 차원')
print(oh_labels.shape)

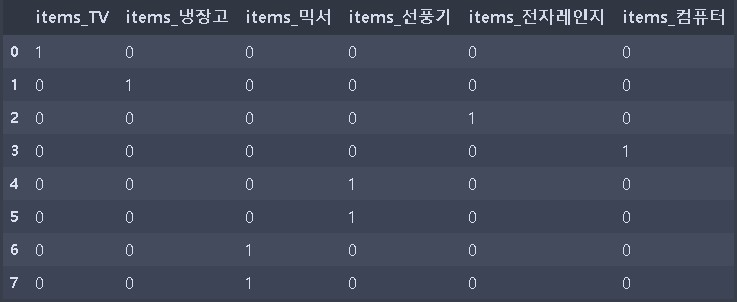
<원-핫 인코딩 - get_dummies()>
OneHotEncoder는 입력 값이 숫자 형이어야하고 2차원 데이터야 한다는 번거로움이 있었다. 하지만 pandas의 get_dummies() API를 이용하면 문자열 값을 바로 원-핫 인코딩할 수 있다.
import pandas as pd
df = pd.DataFrame({'items': ['TV', '냉장고', '전자레인지', '컴퓨터', '선풍기', '선풍기', '믹서', '믹서']})
pd.get_dummies(df)