우선 palindrome을 번역하면 “회문”이란 뜻으로 역순으로 읽어도 같은 말이나 구절 혹은 숫자를 말한다. 따라서 “a”, “aba”, “cc”, “ababa” 모두 역순으로 읽어도 본래 구절과 같으므로 palindrome이라 할 수 있다.
이 palindrome의 특징을 이용하면 DP 문제로 해결할 수 있다. 어떠한 문자열 s가 palindrome일 때, 만약 그 문자열의 앞뒤에 같은 문자가 붙여진다면 그 문자열 또한 palindrome이 된다.
Ex) “abba” -> “habbah”
단, 원래 문자열의 길이가 1일 때, 같은 문자가 연속으로 와도 palindrome이 된다는 것을 잊으면 안된다.
Ex) “a” -> “aa”
따라서, 아래 나올 Solution에서는 palindrome의 시작을 1개일 때, 2개일 때로 나누어 확장시켜나갈 것이다.
<Solution>
classSolution:deflongestPalindrome(self,s:str)->str:n=len(s)maxLen=0ans=""foriinrange(n):# 길이가 홀수인 palindrome 조사
left,right=i,iwhileTrue:if(left>=0andright<n)ands[left]==s[right]:ifmaxLen<right-left+1:maxLen=right-left+1ans=s[left:right+1]left-=1right+=1else:break# 길이가 짝수인 palindrome 조사
left,right=i,i+1whileTrue:if(left>=0andright<n)ands[left]==s[right]:ifmaxLen<right-left+1:maxLen=right-left+1ans=s[left:right+1]left-=1right+=1else:breakreturnans
먼저 palindrome 후보의 센터를 문자열 s 전체를 순회하면서 한번씩 정해진다.
정해진 센터를 기준으로 palindrome이 홀수일 때, 짝수일 때로 나누어 양옆으로 한칸씩 확장해가며 더 긴 palindrome이 되는지 확인한다.
while문 부분은 홀수일 때, 짝수일 때 상관없이 같으므로 함수로 묶어 통일시켜도 무방하다.
시간복잡도는 센터를 정하는 데 O(n), 센터를 중심으로 검사하는데 O(n)이 소요되므로 O(n2)이다.
두 배열이 정렬되어 있으므로 두 배열의 가장 앞에 있는 숫자를 비교하여 더 작은 수를 차례대로 나열하고 중앙값에 해당되는 인덱스에 도달하면 값을 반환하는 방식을 사용했다.
두 배열 길이의 합이 짝수이면 중앙값은 가운데 2개의 평균을 반환하고 홀수이면 가운데 1개의 값만 반환하면 된다는 것을 고려해야 한다.
<Solution>
classSolution:deffindMedianSortedArrays(self,nums1:List[int],nums2:List[int])->float:m=len(nums1)n=len(nums2)merged_array=[]# p1, p2는 각각 nums1, nums2의 인덱스를 가리키는 포인터이다.
p1=0p2=0# 도달해야할 중앙값의 인덱스이다.
pivot=(m+n)//2+1# merged_array에 나열된 숫자의 개수
curr_idx=1whileTrue:# 제한조건에 10^6보다 클 수 없기 때문에 배열이 끝나면 10^6+1 대입
v1=nums1[p1]ifp1<melse1000001v2=nums2[p2]ifp2<nelse1000001ifv1<v2:p1+=1merged_array.append(v1)else:p2+=1merged_array.append(v2)ifcurr_idx==pivot:if(m+n)%2==0:# 총 배열의 길이가 짝수
return(merged_array[-1]+merged_array[-2])/2else:# 홀수
returnmerged_array[-1]curr_idx+=1
두 배열길이의 합 m+n의 절반을 순회한다. n>=m이라 가정하면 시간 복잡도는 O(n)이다.
얼마전에 큰 맘 먹고 정가 300만원에 달하는 델 노트북의 dell XPS 15 9500 모델을 구입했다.
디자인도 무척 마음에 들고 프리미엄 시리즈라 성능도 좋아 높은 만족감과 함께 사용하던 도중 거슬리는 부분이 생겼다.
[증상]
인터넷을 사용하던 도중 화면이 멈추고 마우스, 키보드 모두 작동이 되지 않는다. 동영상이 재생중이었다면 화면은 멈추고 소리만 계속 나오는 증상이었다.
[해결법]
델 공식 홈페이지 검색 결과 노트북 내장 진단 후 그래픽 드라이버를 최신으로 업데이트 하라는 내용이 나온다.
하지만 진단 결과 아무 문제 없었고, 드라이버 또한 전부 최신이었다.
서비스센터에 찾아가야되나 고민 중 구글링을 더 하다가 레딧 사이트에서 같은 증상을 가진 유저의 해결책을 찾았다.
인텔 그래픽 제어 센터에 들어간다. 시작 메뉴에서 “인텔”이라고 치면 나온다.
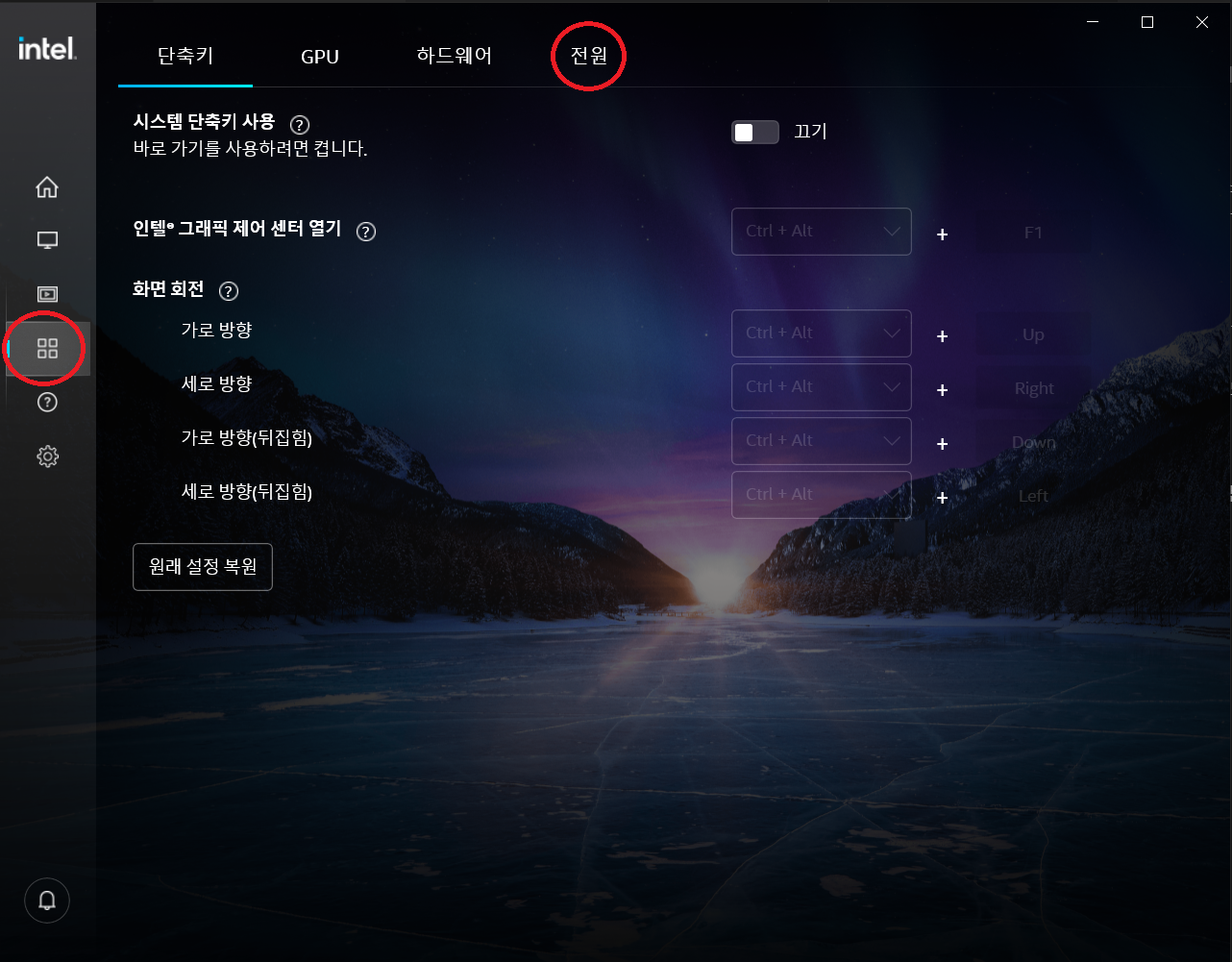
왼쪽 메뉴들 중 사각형 네개가 모여있는 시스템 이라는 메뉴에 들어간다. 오른쪽 위에 전원 버튼을 클릭한다.
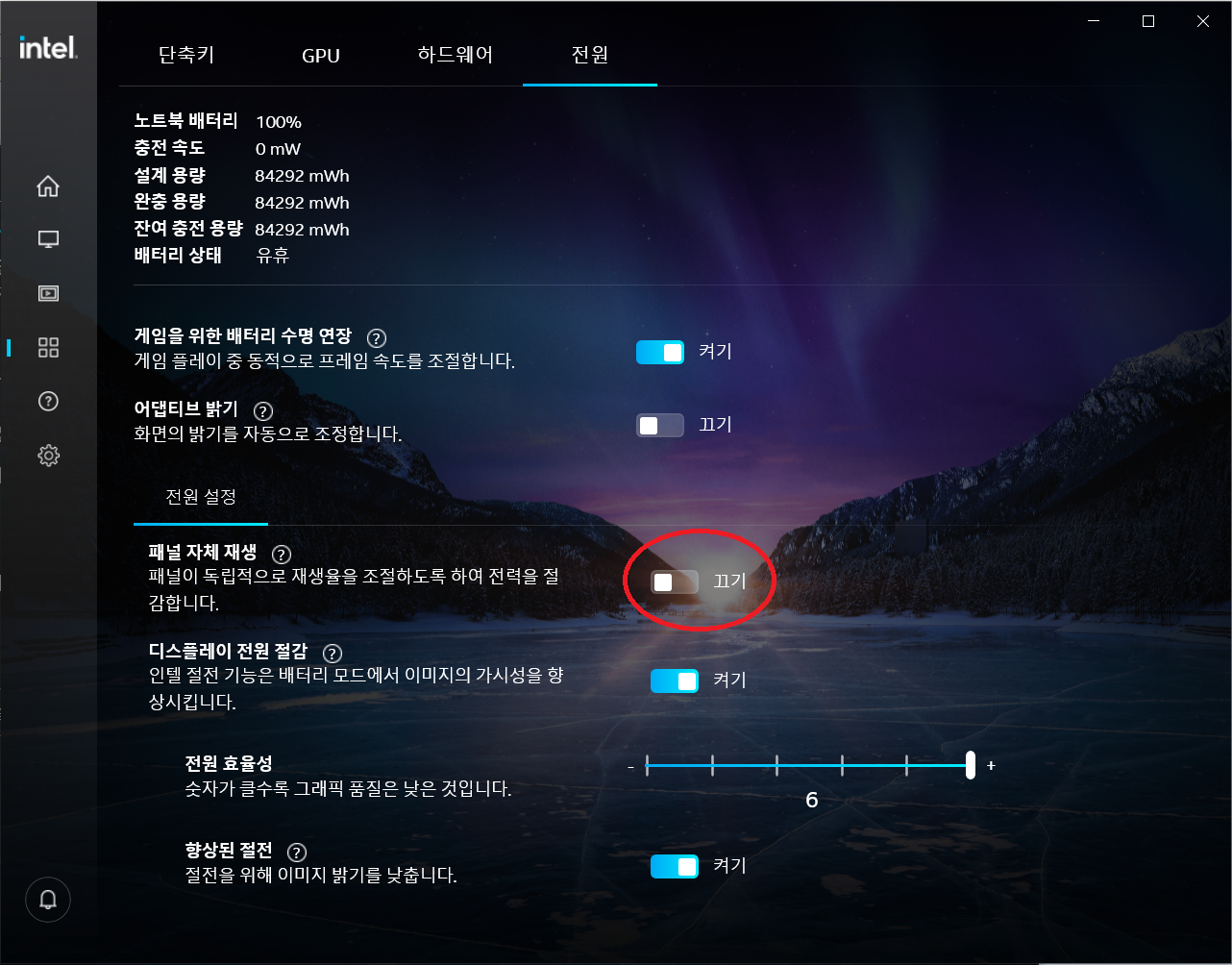
패널 자체 재생 기능을 “끄기”로 바꾼다.
위 과정을 거친 후 더이상 위 증상은 나타나지 않았다. 레딧 댓글들을 보니 XPS 9500 모델에서 많은 유저들이 같은 이슈가 있는 것 같았다. 그리고 델 노트북 뿐만 아니라 인텔 노트북 제품 중 패널 자체 재생 기능을 켜놓은 타 노트북에도 이러한 이슈가 있다는 댓글을 보았다.
이 문제를 비롯하여 문자열 중 어떠한 특징을 지닌 부분문자열의 최대 혹은 최소 길이를 반환하는 문제가 종종 나온다. 이러한 유형의 문제 대부분은 DP로 풀린다.
이 문제의 경우 DP 개념에 부분문자열의 시작과 끝을 정해주는 투 포인터를 적용하여 접근하였다.
<Solution>
classSolution:deflengthOfLongestSubstring(self,s:str)->int:start=0# 부분 문자열의 첫 문자의 index(초기값:0)
dic={}# 문자들의 가장 마지막 위치의 인덱스를 담은 딕셔너리
max_len=0# 나온 길이 중 최대 길이
curr_len=0# 특정 문자 위치에서 가질 수 있는 최장 부분문자열의 길이
fori,vinenumerate(s):ifvnotindic:# 처음 나오는 문자면 dic에 등록하고 현재 길이 1 증가
dic[v]=icurr_len+=1else:# 중복되는 문자가 나왔을 때
ifdic[v]>=start:# 현재 부분문자열 내에 중복되는 문자가 포함
start=dic[v]+1# 시작 인덱스 변경
curr_len=i-dic[v]# 변경된 현재 길이
dic[v]=i# 중복된 문자의 마지막 위치 인덱스 갱신
else:# 현재 부분문자열 내에 포함되지 않아 영향이 없을 때
dic[v]=icurr_len+=1ifcurr_len>max_len:max_len=curr_lenreturnmax_len
문자열을 순회하면서 마주칠 수 있는 case들을 나누어 접근하면 쉽게 생각할 수 있다.
문자가 처음 나왔을 때: 딕셔너리에 새로운 문자 등록, curr_len +1
중복되는 문자가 나오고 현재 부분문자열에 포함될 때: start 및 curr_len 변경
중복되는 문자가 나오고 현재 부분문자열에 미포함일 때: 중복 문자 인덱스 수정 및 curr_len +1
You are given two non-empty linked lists representing two non-negative integers. The digits are stored in reverse order, and each of their nodes contains a single digit. Add the two numbers and return the sum as a linked list.
You may assume the two numbers do not contain any leading zero, except the number 0 itself.
The number of nodes in each linked list is in the range [1, 100]. 0 <= Node.val <= 9 It is guaranteed that the list represents a number that does not have leading zeros.
cf) 조건 중에 leading zero가 없다는 말은 32가 아니라 0032 같이 숫자 앞에 의미 없는 0이 붙어 있지 않다는 뜻이다.
음수가 아닌 정수를 가지고 빈 경우가 없는 연결 리스트가 두 개 주어진다. 숫자들은 역순으로 저장되고, 각각의 노드는 한 개의 숫자를 가진다. 두 연결리스트의 숫자들을 더한 값을 연결리스트의 형태로 반환하라.
갑자기 연결리스트가 등장하여 괜히 어렵게 느껴질 수 있겠지만 조금만 들여다보면 이 문제의 제목인 “Add Two Numbers”처럼 그냥 두 숫자를 더하는 문제임을 알 수 있다. 문제에서 주어진 예시는 다음과 같다.
l1 : [2, 4, 3], l2: [5, 6, 4]
각각의 연결리스트들이 표현하는 숫자는 342, 465 이다. 이 두 개의 숫자를 더한 값인 807을 연결리스트 형태인 [7, 0, 8]으로 반환하는 것이 목적이다.
아직 리트코드 문제 형식이 익숙치 않아 위에 표현된 연결리스트 형태가 int 인자를 담은 리스트로 보여 처음에 혼돈이 왔지만, 문제를 풀고 확인한 결과 연결리스트의 첫 원소인 7을 담은 ListNode 객체를 반환시키면 된다. 뒤에 0, 8 값은 next로 연결되어 있는데 알아서 반환해준다.
처음 시도는 위에 설명한 덧셈 원리로 접근하였다.
[2, 4, 3], [5, 6, 4]를 각각 342, 465로 변환
두 숫자의 합인 807을 다시 연결리스트 형태인 [7, 0, 8]로 변환
결과적으로 Accepted 됐으나, 효율적인 코드도 아니고 이 문제를 낸 취지와 맞지 않는 것 같아서 연결리스트 형태 그대로 문제를 다시 풀어 보았다.
<Solution>
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
classSolution:defaddTwoNumbers(self,l1:ListNode,l2:ListNode)->ListNode:currNode1=l1currNode2=l2# 두 숫자를 더한 값이 10을 넘으면 carry = 1, 아니면 0
carry=0# dummyHead: 반환할 결과값을 담을 객체 그릇
dummyHead=ListNode()output=dummyHeadwhileTrue:ifcurrNode1orcurrNode2:v1=currNode1.valifcurrNode1else0v2=currNode2.valifcurrNode2else0rest=(v1+v2+carry)%10carry=(v1+v2+carry)//10output.next=ListNode(rest)output=output.nextifcurrNode1:currNode1=currNode1.nextifcurrNode2:currNode2=currNode2.nextelse:#마지막 덧셈 후 결과값이 10을 넘겼을 때. ex) 18 + 82 = 100
ifcarry==1:output.next=ListNode(1)breakreturndummyHead.next
이 코드의 경우 최대 l1과 l2 중 더 긴 리스트의 길이를 n이라 할때, 시간 복잡도는 O(n)이다.
파이썬 언어에서 객체의 깊은 복사, 얕은 복사에 대해 생각해 볼 수 있는 문제였던 것 같다.
효율적인 코드를 짜기 위해선 시간 복잡도(Time Complexity)와 공간 복잡도(Space Complexity)를 고려해야 한다. 당연히 시간 복잡도와 공간 복잡도가 동시에 낮을수록 좋겠지만 일반적으로 이 둘의 관계는 Trade-off 관계이다. 그리고 알고리즘 문제는 둘 중 시간 복잡도를 낮추는 방향을 원한다.
위 코드의 경우 최대 n(n-1)/2 번의 검사를 해야 하므로 시간 복잡도는 O(n2) 이다.
이 코드는 nums 배열을 한 번만 순회하면서 해당 순서에 있는 값을 dict에 hashmap의 형태로 저장한다. 그리고 현재 값 v와 dict에 저장된 값들 중 합이 target이 되는지 검사한다.
즉, v + ? = target 이 되는 ? 값이 dict에 저장되어 있는지 확인하면 되므로 target - v 값을 검사한다.
코드 제출 결과 통과 하였다.
이 코드의 경우 최대 nums 배열을 한 번 순회 하므로 시간 복잡도는 O(n)이다.
cf) 파이썬 Dictionary에서 특정 key값을 찾을 때, keys() 배열 전체를 다 뒤져서 찾는 것이 아니라 바로 찾을 수 있다. 이러한 원리로 앞선 방법에 비해 시간 복잡도가 O(n2)에서 O(n)으로 감소하 였다. 파이썬의 Dictionary는 java나 c언어의 HashMap에 해당된다.

![[python] LeetCode 5번: Longest Palindromic Substring(Medium)](/assets/img/leetcode.jpeg)